Overview
ROSE applications operate on EXPRESS-defined data sets in memory. This chapter describes how data sets are organized in memory, how to read and write data sets to disk memory, and other operations.
A RoseDesign object is basic unit of file I/O and holds all of the EXPRESS-defined data objects in a file. A design can be written to disk in several formats, primarily STEP Part 21 text, but also STEP Part 28 XML, or the ROSE working format.
Data Sets In Memory
ROSE applications read and write clusters of EXPRESS-defined data
objects held in RoseDesign objects.
These design
objects hold the data objects and provide
operations that work on multiple objects.
The RoseInterface class defines operations on the entire memory workspace. There is only one instance of this class called the ROSE interface object. You will use its functions for reading designs and managing the designs in memory.
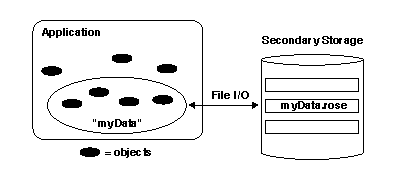
The figure above illustrates a design object. Objects are
considered persistent
if they are owned by a
RoseDesign, because they can be written out to secondary
storage. Objects that are not owned by a RoseDesign are
sometimes referred to as non-persistent
. An object may
belong to only one RoseDesign at any given time.
The RoseDesign class defines functions that operate on the objects owned by a design. Many of these are described in the following sections, as well as Working with STEP Data Objects and Object Search and Traversal.
The ROSE Interface Object
There is one global instance of the ROSE interface object, called
ROSE. The functions are invoked
as ROSE.function(). The interface object keeps track of
the objects in memory, database search paths, EXPRESS data dictionary,
and C++ type information.
You can access a list of designs in memory with the ROSE.workspaceDesigns() function. The ROSE.isInWorkspace() function tells if a design object with a given name exists in memory. The list of designs contains files that you have read and other design objects that hold the compiled data dictionary for an EXPRESS schema. The ROSE.findDesign() function reads a file from disk and returns a pointer to a design object. If the data is already in memory, the function just returns the existing design object.
The ROSE.clearWorkspace() function deletes all normal design objects from memory, but does not remove schema designs. Once a schema has been loaded into memory, it stays in memory for the remainder of the program run. Schema designs are described in more detail below.
Creating and Deleting Design Objects
Create design objects with the new operator. The new design will not contain any objects. Specify a filename or complete path that will be used when the design is saved. The name can contain the full range of international characters encoded as a UTF-8 string.
RoseDesign * d = new RoseDesign (gizmo.stp);
You can give a full or partial path for the design name. If you do not include a filename extension, ".stp" will be used. Creating a design and then doing d->save() gives:
d = new RoseDesign (foo); => ./foo.stp d = new RoseDesign (foo.bar); => ./foo.bar d = new RoseDesign (/baz/foo); => /baz/foo.stp d = new RoseDesign (/baz/foo.bar); => /baz/foo.bar d = new RoseDesign (/baz/foo.bar.stp); => /baz/foo.bar.stp
Each design is has one or more schemas. By default, your design will be associated with the EXPRESS schema used to create the C++ data classes that you are using. The STEP Merged AP and IFC BIM libraries also have "put_schema" functions that fine-tune this information.
// Example using the STEP Merged AP library to make an AP242 design RoseDesign * d = new RoseDesign (gizmo); stplib_put_schema (d, stplib_schema_ap242)
If you are writing a late-bound application (without EXPRESS classes), you can also specify a schema using the EXPRESS name, or a pointer to a schema design. Schemas are represented in memory as special design objects as described in EXPRESS Data Dictionary.
// config_control_design is the name of the AP203 schema RoseDesign * d = new RoseDesign (gizmo,config_control_design);
A design and its contents can be scheduled for deletion
using rose_move_to_trash()
and then deleted when the trash is emptied
using
rose_empty_trash(). The
trash prevents dangling references to deleted objects. When the trash
is emptied, all data objects in all designs are examined and
references to non-persistent or trashed objects are set to null.
Alternatively, a design can be deleted immediately using the C++ delete operator, but this does not check other objects for pointers to freed memory, which could cause core dumps or other problems, particularly when writing designs to secondary storage.
The RoseDesign::emptyYourself() function deletes all data objects in a design. As with the delete operator, use of this function may result in dangling references to the deleted data objects.
RoseDesign * design; /* preferred way to remove */ rose_move_to_trash (design); /* schedule for deletion */ rose_empty_trash(); /* safe deletion */ /* alternate way to remove, but not as safe */ design-> emptyYourself(); /* delete all data objects */ delete design; /* delete entire design */
Reading and Writing Design Objects
Read files with the RoseInterface::findDesign() function. It checks if the file is already in memory before trying to read it from disk. It returns a RoseDesign pointer or null if no match is found.
Give the function a complete filename with a directory. The filename can contain the full range of international characters encoded as a UTF-8 string. The function will look for the exact filename first. Then, if you give a name without an extension, it will try known ones like ".stp", ".step", and ".ifc".
If you give a name with no directory, the function will search search a series of directories. If the name does not have an extension, the function will try each known one first, then try the name without an extension.
// find examples design, current design is unchanged RoseDesign * d = ROSE.findDesign (/home/examples.stp); // find examples design, already in memory from above d = ROSE.findDesign (examples);
Use RoseInterface::findDesignInWorkspace() to only look at designs already in memory. The function searches for a design that was read from a particular full path if given, otherwise it tries to match the name portion of the path.
RoseDesign * d; d = ROSE.findDesignInWorkspace (gizmo); // This only returns a design read from "bar/foo" d = ROSE.findDesignInWorkspace (bar/foo); // This can return a design read from "./foo", "bar/foo", // or "baz/foo". If all three are in memory, it returns // the first one read. d = ROSE.findDesignInWorkspace (foo);
Call RoseDesign::save() to write a design to disk. The RoseDesign::path() string is the exact filename that it will be written to. If no directory is given, a design will be written to the current directory. The RoseDesign::name() function can also take a full or partial path information. It only changes the directory or extension if one is given.
RoseDesign * d;
// will be saved as ./hello.stp
d = new RoseDesign("hello");
d-> save();
// will be saved as foo/hello.bar
d = new RoseDesign("foo/hello.bar");
d-> save();
// will be saved as foo/hello.bar
d = new RoseDesign("hello");
d-> path("foo/hello.bar");
d-> save();
// will be saved as foo/goodbye.bar
d = new RoseDesign("foo/hello.bar");
d-> name("goodbye");
d-> save();
The RoseDesign access functions for path() returns the complete file path string, while fileDirectory(), name(), and fileExtension() return the components of it.
RoseDesign * design; /* get and set the design name */ const char * nm = design-> name(); design-> name (gizmo); /* get and set the complete file directory */ const char * dir = design-> fileDirectory(); design-> fileDirectory (/home/datadir); /* get and set the complete file extension */ const char * ext = design-> fileExtension(); design-> fileExtension (foo); /* get and set the complete file path */ const char * p = design-> path(); design-> path (/home/datadir/gizmo.foo);
Calling RoseDesign::saveAs() behaves like calling name() to change some or all of the path, saving, then setting the everything back to the original.
// will be saved as ./backup.stp
d = new RoseDesign("hello");
d-> saveAs (backup.stp
);
ST-Developer applications read and write files in STEP Part 21 format. The complete list of available formats is documented with the RoseDesign::format() function.
File Search Paths
If you only give a partial filename (no directory or extension) to findDesign(), the ROSE library will try to find the design in a search path of directories.
RoseDesign * d; d = ROSE.findDesign (/usr/data/tutorial.step); /* reads directly */ d = ROSE.findDesign (tutorial); /* search for .stp, .step, .ifc, etc */ d = ROSE.findDesign (tutorial.step); /* search for tutorial.step */
The ROSE library searches for compiled EXPRESS schemas using this
search path. By default, the path contains the current directory
(.
), a local schemas directory
(./schemas
), and the ST-Runtime schemas directory.
If you can set a custom path using the $ROSE_DB environment
variable. This contains a list of directories separated by a colon
(:
) on UNIX, a semicolon (;
) on
Windows and a comma on VMS (,
). The following
example show a path on a UNIX machine:
% setenv ROSE_DB .:/usr/local/designs:/usr/local/schemas
The first directory in the search path is usually the current
directory (.
). The library always appends the
ST-Runtime schemas directory to the path. The schemas directory be
changed using rose_get/setenv
system_schema_path().
An easy way to see the contents of your search path from the command line is to use the rose ls utility. This will display all directories in the search path, and all the design files within those directories:
% rose ls Total number of designs:: 26 In /usr/local/steptools/system_db/schemas config_control_design.rose iges_annotation_schema.rose iges_boundary_representation_schema.rose iges_constructive_solid_geometry_schema.rose iges_curve_and_surface_geometry_schema.rose iges_structure_schema.rose iges_types_schema.rose [ ... etc ... ]
When searching directories, the library uses filename extensions to distinguish design files from other files. When a filename ends in .step, .stp, .p21, or .pdes, it is considered to be a STEP Part 21 file. If a filename ends with .rose or .ros, it is a ROSE Working Form file.
The RoseInterface::pathDesignNames() function returns a list of all files in the search path with recognized extensions, or in a particular directory if you specify one. The RoseInterface::isInPath() function tests whether a design with a particular name is in the search path.
ListOfString * names; names = ROSE.pathDesignNames(); /* all designs in path */ names = ROSE.pathDesignNames(/usr/data); /* only one directory */ if (ROSE.isInPath (gizmo)) { /* do something */ }
The RoseInterface::path() function returns a list of directories in the search path. The RoseInterface::usePath() function sets the search path from within an application. This function takes a string containing the individual directory names.
ListOfString * dirs = ROSE.path(); /* get path */
unsigned i, sz;
for (i=0, sz=dirs->size(); i<sz; i++)
printf (path [%d] %s\n
, i, dirs->get(i));
ROSE.usePath (.:./schemas:/usr/myapp/schemas
; /* set path */
Memory Cleanup Functions
The ROSE library creates internal indicies and runtime type information to link EXPRESS definitions and C++ classes. Some of this is set when static constructors are called and some on first access to STEP data. The library also reads compiled data-dictionary information.
This information is used throughout the life of the application. Normally, releasing these indicies is unnecessary because memory is released on application exit.
However, checkers may report this information as memory
leaks
so RoseInterface has two functions for releasing
system memory at the end of your application:
ROSE.shutdown(); ROSE.shutdown_everything(); /* permanent */
The RoseInterface::shutdown() function releases all persistent data in memory, and restores the ROSE library to pre-startup condition. If you want to, you can read designs back into memory again and continue processing.
The RoseInterface::shutdown_everything() function releases all persistent data in memory, as well as all runtime C++ type information created by static constructors. Once this is done, you should not make any more calls to the ROSE library.
Current Design
An application can operate on many designs at once, and will
usually pass around a RoseDesign pointer. The ROSE interface
object can designate a default, called the current
design,
which allows for slightly simpler object creation with "pnew"
rather than "pnewIn" with a design pointer.
The RoseInterface::design() returns the current design pointer. The useDesign() function calls findDesign() if necessary and sets the current design, while newDesign() creates a new design and sets it as the current design. Only useDesign() and newDesign() change the current design.
RoseDesign * d; ROSE.useDesign (d); /* set current design */ ROSE.useDesign (gizmo); /* read and set current design */ ROSE.newDesign (hello); /* create and set current design */ d = ROSE.design(); /* get current design */ // pnew uses the current design, pnewIn takes an explicit pointer point * foo = pnew point; point * bar = pnewIn(d) point;
STEP Part 21 Exchange Files
All ST-Developer applications can read and write STEP Part 21 ASCII exchange files (ISO 10303-21). The library can read and write files using the 1994 original, the 1996 update, the 2002 second edition, and the most recent 2016 third edition. See Alternate Versions and Conformance Classes for more information.
A STEP Part 21 file has a header section with identifying information, and a data section with the information to be transferred. The outline of a STEP file is shown below:
ISO-10303-21; /* opening keyword */ HEADER; /* header section */ [ ... header infomation ... ] ENDSEC; ANCHOR; /* anchors, third edition files */ <6db46031-4fab-4838-824b-91cea43922e4>=#10; <3c9773de-5015-4c05-86b4-0e35a5bfd96f>=#7934; <some-other-name>=#8347; [ ... name / entity id pairs ... ] ENDSEC; DATA; /* data section */ [ ... entity instances ... ] ENDSEC; END-ISO-10303-21; /* closing keyword */
A STEP file becomes a design object in memory and entity instance becomes a C++ object owned by the design. The header data is available through the header section functions. The entity identifier information for these objects is available through the entity identifier functions. The design also has a dictionary containing all of the anchor section information.
Header Section Information
Header section information from STEP Part 21 exchange files is available to applications. The STEP specification says that the header of each exchange file should contain one each of the following objects:
ENTITY file_description;
description : LIST [1:?] OF STRING (256);
implementation_level : STRING (256);
END_ENTITY;
ENTITY file_name;
name : STRING (256);
time_stamp : STRING (256);
author : LIST [1:?] OF STRING (256);
organization : LIST [1:?] OF STRING (256);
preprocessor_version : STRING (256);
originating_system : STRING (256);
authorization : STRING (256);
END_ENTITY;
ENTITY file_schema;
schema_identifiers : LIST [1:?] OF STRING(256);
END_ENTITY;
A sample STEP file header section is shown below. The
implementation level, timestamp, and preprocessor fields are
automatically set by the system (noted by SYS
) whenever
you write a file.
HEADER;
FILE_DESCRIPTION (
('Sample NURBS geometry for a Boeing 707', /* description */
'for the Common STEP Tasks tutorial'),
'2;1'); /* impl level (sys) */
FILE_NAME (
'ap203_database', /* name */
'2011-07-14T14:18:59-04:00', /* timestamp (sys) */
('Sam Sample'), /* author */
('STEP Tools Inc.', /* organization */
'Troy, New York 12180',
'info@steptools.com'),
'ST-DEVELOPER v14.0', /* preprocessor (sys) */
'SampleCAD v123', /* originating system */
''); /* authorization */
FILE_SCHEMA (('CONFIG_CONTROL_DESIGN')); /* schema (sys) */
ENDSEC;
The FILE_SCHEMA information represents schemas given to the design by the useSchema() and addSchema() functions. The FILE_DESCRIPTION and FILE_NAME information can set directly by an application.
The RoseDesign::header_description() function returns a file description object. This object indicates the contents of the exchange file, along with the version of ISO 10303 that was used to create it. As shown above, the library supplies the value for the implementation_level field when writing the file. Any value you put in there will be ignored.
The RoseDesign::header_name() function returns the file name object. This provides information about the person and systems that created the exchange data. The library supplies the values for the time_stamp and preprocessor_version fields, and will initialize the name field with the design name.
When you create a new RoseDesign object, the header objects are null. The RoseDesign::initialize_header() function creates the header objects and initializes the fields. The example below creates a design and fills in the header information:
/* create the design */ design = new RoseDesign (camshaft,config_control_design); /* use Part 21 when writing it out */ design-> format (p21); /* fill in the header information */ design-> initialize_header(); /* implementation_level field is taken care of by the * tool kit. */ design-> header_description()-> description ()-> add (This file contains the design for widgets); /* name, time_stamp, and preprocessor_version fields * are taken care of by the tool kit. */ design-> header_name()-> originating_system (MonkeyCad 2.3); design-> header_name()-> author ()-> add (Sam Simian); design-> header_name()-> organization()-> add (Monkey International); design-> header_name()-> authorisation (Sam's Boss);
Short Names
The STEP EXPRESS schemas each have a file containing abbreviated entity names. These short names can be used in a STEP physical file to reduce the amount of space used. Below are some of the short names for AP203. The aliases are given as a comma-separated pair of names with the long name first.
AXIS1_PLACEMENT,AX1PLC AXIS2_PLACEMENT_2D,A2PL2D AXIS2_PLACEMENT_3D,A2PL3D BEZIER_CURVE,BZRCRV BEZIER_SURFACE,BZRSRF BOUNDARY_CURVE,BNDCR BOUNDED_CURVE,BNDCRV BOUNDED_SURFACE,BNDSRF BREP_WITH_VOIDS,BRWTVD B_SPLINE_CURVE,BSPCR B_SPLINE_CURVE_WITH_KNOTS,BSCWK
The STEP file processor looks for abbreviation files of the form <schema>.nam in the database file search path. These are normally installed as part of ST-Runtime.
The following is a portion of an AP203 file that uses short names:
#9100 = CRTPNT((0.0,0.0,0.0)); #9101 = DRCTN((1.0,0.0,0.0)); #9102 = DRCTN((0.0,1.0,0.0)); #9103 = DRCTN((0.0,0.0,1.0)); #9120 = A2PL3D(#9100,#9103,#9101); #9121 = PLANE(#9120); #9122 = CIRCLE(#9120,30.0); #9123 = CRTPNT((30.0,0.0,0.0)); #9124 = VRTPNT(#9123); #9125 = EDGCRV(#9124,#9124,#9122,.T.);
The library can read files with short names as long as the alias file is present. Files are normally written with the complete names, because that is the most portable. You can write files with short names by changing the RoseP21Writer::use_short_names preference setting.
Entity Identifiers
Each entity instance in the data section of a STEP file has an integer identifier. These are the #nnn numbers that reference objects in the file. When a file is read, entity instances are converted to C++ objects and references are turned to C++ pointers. Nevertheless, the original entity id number can be useful for printing debugging information.
The RoseObject::entity_id() function returns the original entity id number for an object. IDs are only available for entities that are read from STEP physical files. This function returns zero for aggregates, selects, and any object read from a ROSE working form file.
RoseObject * obj; printf (This is entity #%d\n, obj-> entity_id());
The entity id is not a permanent identifier. The number is unique within a STEP Part 21 file, but not between files. By default, entities are automatically renumbered when written to disk. An application can control this renumbering and preserve the IDs if necessary. Consult Customized File Handling for details.
External Mappings
EXPRESS has a notion of AND/OR complex inheritance, where an instance can have a set of types. In practice, this is operates just like multiple inheritance, but without an explicit type name for the combination.
In STEP data, these type of instances appear in common things like
units, contexts, and NURB curves and surfaces. The instances are
written to a STEP file in a special way. Normal instances have a
single, explicit type name and are written using the internal
mapping
where the type name is followed by a list of attributes
in superclass-to-subclass order. The following are some entities
written using the internal mapping.
#57=DATE_AND_TIME(#58,#59); #58=CALENDAR_DATE(1993,17,7); #59=LOCAL_TIME(13,47,28.0,#29);
Since an AND/OR complex instance has a set of types, they are
written using something called an external mapping.
. This
is a parenthesized list of each type, including any supertypes, sorted
into alphabetical order. Each type holds just the attributes locally
defined by that type. The example below shows the STEP file entry for
an object that is both a B-Spline Surface with Knots and a Rational
B-Spline Surface.
#10 = ( BOUNDED_SURFACE () B_SPLINE_SURFACE (3, 3, ((#20, #60, #100, #140), (#30, #70, #110, #150), (#40, #80, #120, #160), (#50, #90, #130, #170)), $, .F., .F., .F.) B_SPLINE_SURFACE_WITH_KNOTS ($, $, (0., 0., 0., 0., 1., 1., 1., 1.), (0., 0., 0., 0., 1., 1., 1., 1.), $) GEOMETRIC_REPRESENTATION_ITEM () RATIONAL_B_SPLINE_SURFACE (((1., 1., 1., 1.), (1., 1., 1., 1.), (1., 1., 1.,1.), (1., 1., 1., 1.))) REPRESENTATION_ITEM () SURFACE () );
All supertypes are listed, even ones that have no attributes. If you are reading in a STEP physical file that has a new combination, the ROSE library will create new data dictionary information for the combination and try to match it to an existing C++ class. It will look for a combination of a subset of types if the full combination is not available, or a combination with a supertype if one with a subtype is not available. This matching process is described in Best-Fit Classes.
Customized File Handling
Applications that need detailed control over Part 21 file handling may take advantage of the features described in the following sections. The classes that handle Part 21 reading, (RoseP21Lex and RoseP21Parser) and the class that handles writing (RoseP21Writer), have a number of hooks and settings that applications can use to customize file handling.
These hooks are described in the following sections. They can select different versions of the Part 21 standard, alter the writing of schema identifiers, change the numbering of entities, scan the comments in a file, put up a status bar, and other useful things.
Alternate Versions and Conformance Classes
The original Part 21 specification was issued in 1994, and shortly thereafter a technical corrigendum was published to correct some errors in the way that selects were handled. This technical corrigendum or TC version is what is in common use today.
A second edition of the Part 21 was published in 2002. This is upwards compatible, so existing files remain valid. Under the new edition, files may contain extra context information in the header, and more than one data section.
In the header section of a file, the FILE_DESCRIPTION has an
implementation level field which identifies the version of the Part 21
specification. In an original 1994 file, this field contains
1
, in a TC file and second edition file without extra
features, it contains 2;1
, and in second edition file with
new features it contains 3;1
.
ISO-10303-21;
HEADER;
FILE_DESCRIPTION ( ('descriptive text'), '2;1' );
...
By default, files are written using the TC specification for compatibility with older applications. However, if the data set uses second edition features such as the following, it will be automatically written out as a second edition file:
- multiple data sections (as described in the following section)
- only one data section, but the data section has a name.
- extra header section information using the section_context, section_language, or file_population entities.
The RoseP21Writer::use_spec_version() class function and related max/min functions control which version is used to write files. These expect the symbols below:
PART21_IS— original 1994 version, replaced shortly after publication by the TCPART21_TC— revised, technical corrigendum version published in 1996. The most commonly used version.PART21_ED2— second edition of Part 21, published in 2002. Adds support for multiple data sections in a file.PART21_ED3— third edition of Part 21, published in 2016. Adds file ANCHORs and ZIP archive support.
The max_spec_version() and and min_spec_version()
functions set the upper and lower limit for the allowable versions.
The use_spec_version() function sets the upper and lower limit
to the same value. By default, the minimum version
is PART21_TC and the maximum version
is PART21_ED2.
To preserve anchors, set the max to PART21_ED3. If
you need to write a file for use with an application from 1995 that
expects the original IS encoding for SELECT values, you can set the
upper and lower to PART21_IS.
// Default behavior, try ISO 10303-21:1994, Corr 1:1996, // but use ISO 10303-21:2002 (Edition 2) if needed RoseP21Writer::max_spec_version (PART21_ED2); RoseP21Writer::min_spec_version (PART21_TC); // Force files to use original ISO 10303-21:1994 RoseP21Writer::use_spec_version (PART21_IS);
The Part 21 specification supports two different conformance classes. These conformance classes determine how entity instances are written to a file.
Under conformance class one, only complex entity instances are written using an external mapping, while all other entities are written using the internal mapping. This is the default behavior for ST-Developer and other STEP processors. Under conformance class two, which is rarely used, all entities with supertypes are written using the external mapping.
You can control this behavior using
the RoseP21Writer::use_conformance_class()
static function. The symbol
PART21_INTERNAL_CC indicates indicate Part 21 conformance
classes one (CC1), while PART21_EXTERNAL_CC indicates
conformance classes two (CC2). For maximum compatibility, this should
remain at the default setting of CC1.
static void RoseP21Writer::use_spec_version (unsigned); /* default conformance class */ RoseP21Writer::use_conformance_class (PART21_INTERNAL_CC); /* write everything as an external mapping */ RoseP21Writer::use_conformance_class (PART21_EXTERNAL_CC);
Customized Schema Handling
An application can customize the handling of schemas in a file by supplying a hook function. When reading the header section of a Part 21 file, this hook will be called with a list of each schema name in the FILE_SCHEMA() object. This function takes a design pointer and a list of schema names, and should find the appropriate compiled schemas and add them to the design. A return value of ROSE_OK indicates successful completion while a non-zero value indicates an error.
The variable RoseP21Parser::set_schemas_fn holds a pointer to the function. If the set_schemas_fn pointer is null, the rose_p21_dflt_add_schema() will be called for each name in the schema list.
RoseStatus custom_set_schemas (
RoseDesign * design,
ListOfString * all_schemas
)
{
if (!all_schemas || !all_schemas-> size()) {
printf ("NO SCHEMAS\n");
return ROSE_IO_BAD_SCHEMA;
}
unsigned i, sz;
for (i=0, sz=all_schemas->size(); i<sz; i++) {
const char * sname = all_schemas-> get(i);
/* like findDesign(), but ignores case and ASN/1 idents */
RoseDesign * schema = rose_p21_find_schema (sname);
if (schema) {
design-> addSchema (schema);
}
return ROSE_IO_BAD_SCHEMA;
}
return ROSE_OK;
}
// Somewhere in your main
RoseP21Parser::set_schema_fn = custom_set_schemas;
The older RoseP21Parser::add_schema_fn hook is deprecated because the set_schemas_fn hook is more flexible, can test for missing schemas, and look at combinations of names.
When writing a design, a hook function can provided to supply the names of each schema in a design. The function will be called on each element of the schemas() list of the design. If the function returns null for a particular schema, no entry will be written for it in the Part 21 FILE_SCHEMA list.
The RoseP21Writer::schema_name_fn static class variable holds a pointer to the function. The function will be passed two arguments, a pointer to the design being written, and a pointer to the schema (which is also a design). If the schema_name_fn pointer is null, the default behavior is used.
typedef const char * (*RoseP21SchemaNameFn) (
RoseDesign * design,
RoseDesign * schema,
);
static RoseP21SchemaNameFn RoseP21Writer::schema_name_fn;
const char * a_simple_write_schema_function (
RoseDesign * /* design, unused */,
RoseDesign * schema
)
{
return schema-> name();
}
Behavior on Missing Schemas
If the Part 21 reader can not find the compiled schema definitions for a file, it will probably not be able to process many of the instances in the file. If you are using the set_schemas_fn hood described above, you can flag an error and stop the read with the return value of your function. When using the default schema handling (no hook function), you can control the behavior with the following flag.
static RoseBoolean RoseP21Parser::allow_bad_schemas; /* try to keep reading, even with missing schema */ RoseP21Parser::allow_bad_schemas = ROSE_TRUE; /* (default) generate an error, do not continue reading */ RoseP21Parser::allow_bad_schemas = ROSE_FALSE;
The RoseP21Parser::allow_bad_schemas variable controls the behavior of the file reader if a schema is not found. By default, this variable is set to false, and if schema cannot by found, the filer generates a single error for the schema itself, and the RoseDesign that is returned from ROSE.findDesign() is NULL.
If this variable is set to true, the filer attempts to read as much as it can. If schemas are missing, it unlikely to find the compiled EXPRESS definition for many entities. When it can not find a definition, it will issue a warning and skip the instance. This may result in many messages and a RoseDesign containing no instances.
Entity ID Numbering
By default, the Part 21 file writer numbers all entity instances in increments of one (#10, #11, #12, etc.). It assigns new numbers each time the file is written. Your application can control how these numbers are assigned and the order in which the instances appear in the file using the facilities described below.
Entity ID Preservation
By default, entities are renumbered when they are written, but the library can also preserve the entity ids across reads and writes. The options below control the default entity numbering provided by the rose_p21_dflt_renumber() function. If you have provided a custom renumber function described below, these options have no effect. This functionality is controlled by the following static members of the RoseP21Writer class.
static RoseBoolean RoseP21Writer::preserve_eids; /* save eids from input file */ RoseP21Writer::preserve_eids = ROSE_TRUE; /* (default) renumber all entities, most effiecient */ RoseP21Writer::preserve_eids = ROSE_FALSE;
The RoseP21Writer::preserve_eids static class variable controls how entities are assigned IDs (the #numbers) in a file. If true, any entity instance that was read in from a file will keep the same IDs that it had in that file. An application can also assign its own IDs to newly created instances when they are created. Newly created instances that do not have an ID will be assigned one that does not conflict with any existing IDs.
If false, all entity instances are given a new ID. Preserving IDs can slow down the creation of Part 21 files, so this variable is set to false by default.
static RoseBoolean RoseP21Writer::sort_eids; /* only write instances sorted by ID */ RoseP21Writer::sort_eids = ROSE_TRUE; /* (default) write in the most efficient way */ RoseP21Writer::sort_eids = ROSE_FALSE;
The RoseP21Writer::sort_eids static class variable controls the order in which entity instances are written to a Part 21 file. By default, the instances are written in the most efficient manner, which may or may not be sorted. In general, the entities will be sorted, since the writer assigns IDs to the instances and then to write them in the same order. If you are using the preserve_eids described above to save IDs from an existing file, then writing using the most efficient traversal may result in instances appearing in a random order. An unsorted Part21 file may look strange to a human reader, but it is perfectly legal according to the Part 21 specification.
If you are using preserve_eids and want to force the instances to be written in numeric order, set the sort_eids variable to true. This forces the library to build an index of the IDs before writing the file, which is somewhat expensive.
static unsigned int RoseP21Writer::renumber_density; /* Ratio of entities/max eid */ RoseP21Writer::renumber_density = 5;
The RoseP21Writer::renumber_density static class variable determines how new object are numbered. For any instance that does not have an EID, there are two possibilities: the greatest EID in the file can be found, and all new EIDs are chosen as increments from that, or gaps in the numbering sequence can be located.
The first of these options is fast, but may lead to the EIDs eventually overflowing, the second option is safe, but requires the creation of an index. The algorithm to use is determined by the value of the renumber_density variable. If the greatest EID in the model divided by the number if entity instances in the model is greater than renumber_density, then the gaps are filled, otherwise the values are appended to the file. The default value is 5.
Batch Renumbering
An application can provide a function that will be called before writing begins and should traverse the entire design, assigning new ids with the RoseObject::entity_id() function. The variable RoseP21Writer::renumber_fn holds a pointer to an application-provided function. If the pointer is null, the default behavior is used. The function should return ROSE_OK to indicate successful completion.
typedef RoseStatus (*RoseP21RenumberFn) (RoseDesign * design); static RoseP21RenumberFn RoseP21Writer::renumber_fn;
The following hook function demonstrates how to renumber the objects by increments of five. This function uses a RoseCursor to visit every entity in the data sections of a design.
RoseStatus renumber_by_five (RoseDesign * design)
{
RoseCursor objects;
register RoseStructure * object;
register unsigned long eid = 5;
/* Traverse entities in all data sections. Seting the
* cursor section type is not really needed since data sections
* are the default */
objects.traverse (design);
objects.section_type (ROSE_SECTION_DATA); /* the default */
objects.domain (ROSE_DOMAIN(RoseStructure));
/* number the entity ids by 5s */
while (object = (RoseStructure *) objects.next()) {
object-> entity_id (eid);
eid += 5;
}
return ROSE_OK;
}
/* to use this function, be sure to set renumber_fn */
RoseP21Writer::renumber_fn = renumber_by_five;
/* reset to default behavior */
RoseP21Writer::renumber_fn = 0;
Reading and Writing Comments
An application can add comments to the header section of a Part 21 file and to individual entity instances. Comments on individual entity instances are not useful for production files, but could be very helpful when creating sample datasets for training or documentation purposes.
To add comments to instances in a file, just call the RoseObject::entity_comment() function with the contents of the comment. Given the following fragment:
calendar_date * cd; local_time * lt; cd-> entity_comment (This is my date instance); lt-> entity_comment (This is\n...my time instance\n);
When the instance is written out to a STEP Part 21 file, the comment would appear as follows:
/*This is my date instance*/ #58=CALENDAR_DATE(1993,17,7); /* This is ...my time instance */ #59=LOCAL_TIME(13,47,28.0,#29);
When reading, comments are normally discarded and entity_comment() will just return null, but you can force the file processor to save them by using the RoseP21Lex::comment_fn static class variable, which holds a pointer to function to scan the comments in a Part 21 file.
By default, the variable is null and the function rose_p21_read_and_discard_comment() is used to read and ignore comments. The rose_p21_read_and_preserve_comment() captures a comment and associates it with the nearest object so that it is available via RoseObject::entity_comment().
/* somewhere in your main, before you start reading files */ /* save comments for later use with entity_comment() */ RoseP21Lex::comment_fn = rose_p21_read_and_preserve_comment; /* default behavior, discard comments */ RoseP21Lex::comment_fn = NULL; RoseP21Lex::comment_fn = rose_p21_dflt_read_comment; /* alias */ RoseP21Lex::comment_fn = rose_p21_read_and_discard_comment;
When writing a file, your application can add comments to the header section of a file, to identify the product in more detail than allowed by the FILE_NAME() entry, or for documenting internal settings for debugging purposes.
The variable RoseP21Writer::comment_fn holds a pointer to a function that will be called while writing the beginning of the header section. The function is called with a pointer to the file being used.
typedef RoseStatus (*RoseP21WriteCommentFn) (FILE * file);
static RoseP21WriteCommentFn RoseP21Writer::comment_fn;
/* EXAMPLE */
RoseStatus write_custom_comment (FILE * file) {
fprintf (file, /* Produced by MonkeyCAD\n
);
fprintf (file, * Debugging Information:\n
);
. . .
fprintf (file, */
);
return ROSE_OK;
}
/* somewhere in your main() */
RoseP21Writer::comment_fn = write_custom_comment;
Periodic Status Updates
The Part 21 reader and writer functions can periodically call a hook function to implement a status bar. Calling frequency is specified as a number of objects. A frequency of 100 means the status function will be called after every 100 objects are read or written. A value of 1 means the function will be called after every object.
The variables RoseP21Parser::status_fn and RoseP21Writer::status_fn hold pointers to application-provided status functions. The variables RoseP21Parser::status_freq and RoseP21Writer::status_freq hold the calling frequency. If the calling frequency is zero or the function pointer is null, the status function will not be called.
typedef RoseStatus (*RoseP21ReadStatusFn) (
RoseP21Parser * parser_obj,
unsigned long current_entity_count
);
typedef RoseStatus (*RoseP21WriteStatusFn) (
RoseP21Writer * writer_obj,
unsigned long current_entity_count
);
static RoseP21ReadStatusFn RoseP21Parser::status_fn;
static unsigned RoseP21Parser::status_freq;
static RoseP21WriteStatusFn RoseP21Writer::status_fn;
static unsigned RoseP21Writer::status_freq;
The status functions return a RoseStatus. Successful completion is indicated by the value ROSE_OK. A non-zero value indicates failure and further file processing is halted. Thus, the status function could put up a status bar with a cancel button. Normally the function would return ROSE_OK, but when the button is pressed, the function could return a non-zero value, halting the read or write.
International Character Support
The ROSE library represents all international character strings as UTF-8 in memory. When reading or writing Part 21 files, the library converts between UTF-8 and the Part 21 character encoding. No additional action is needed.
The Part 21 specification predates UTF-8, so Unicode / ISO 10646 characters appear in the exchange file as a different notation, using the \X2 and \X4 escape sequences as shown in the example below. The library can also read Part 21 files with ISO 8859 "code page" characters and convert them to Unicode in UTF-8 strings. In a Part 21 file, ISO 8859 values appear as \S\ and \P\ escape sequences. When strings are written back out, they will be written as Unicode values rather than ISO 8859.
#10=DIRECTION('Greek Data: \X2\039803C8\X0\',(0.,1.,0.));
Line Wrapping
When writing STEP files, the ROSE library will normally wrap lines so that they are not longer than 70 characters. The STEP Part 21 file format explicitly ignores line break characters (ISO 10303-21 clause A.2), so lines can be as long or short as desired.
Wrapping lines at 70 characters is actually very important to
prevent email systems from corrupting STEP, IFC, and CIS/2 files if
they are mailed without first zipping them. Email software will strip
or double periods in a message, usually when they appear as the first
character of a line. If you mail a file as an attachment and did not
wrap the lines yourself, the mailer will, and if a number or enum
value happens to be the first thing in the line, it could be make the
syntax bad (.F. to ..F. or F.)
or (.123 to ..123 or even
worse 123!) and the system on the other side will not be
able to read them. Zipping files avoids this, but your customers will
probably not do so.
We recommend that you leave this behavior at the defaults, but using the RoseP21Writer::fill_column variable, you can set the fill column to a different value or disable wrapping completely by setting it to zero.
RoseP21Writer::fill_column = 70; /* recommended value */ RoseP21Writer::fill_column = 1; /* one char per line! */ RoseP21Writer::fill_column = 0; /* no wrapping, watch for email corruption */
STEP Part 28 XML Files
ST-Developer applications can read and write STEP Part 28 XML exchange files (ISO 10303-28:2007). To enable this, link against the rosexml and rosemath libraries, include rose_p28.h, and call rose_p28_init() at the start of your program to register the XML reader and writer.
From then on, your application will automatically recognize STEP
Part 28 XML files when reading. By default, new files are written as
Part 21 but you can switch to Part 28 XML by calling
RoseDesign::format() with p28
or
p28-raw" strings.
RoseDesign * d; d-> format (p21); d-> save() // write as Part 21 text d-> format (p28); d-> save() // write compressed Part 28 XML d-> format (p28-raw); d-> save() // write raw Part 28 XML
When the p28
format is specified, the XML will be zip
compressed to reduce size, and the file will be given
the .p28
extension if none is specified. If you run
unzip on the result, you will see a single file
called iso_10303_28.xml, which contains the raw XML.
With the p28-raw
format is specified, the XML will be written without any compression, and the file will be given the .xml
extension if none is specified.
The small Part 28 XML file below shows some AP238 instance data with an axis placement, cartesian point, and two directions. The specifics of the Part 28 encoding are discussed in XML Configuration below.
<?xml version=1.0?> <iso_10303_28_terse xmlns=urn:oid:1.0.10303.238.1.0.1xmlns:exp=urn:oid:1.0.10303.28.2.1.1xmlns:xsi=https://www.w3.org/2001/XMLSchema-instanceschema=integrated_cnc_schema> <exp:header> <exp:name>dataset</exp:name> <exp:preprocessor_version>stepnc writer</exp:preprocessor_version> </exp:header> <!-- instance data --> <Axis2_placement_3d id=id1Name= Location=id2Axis=id3Ref_direction=id4/> <Cartesian_point id=id2Name=locCoordinates=3.5 -3.5 -4.16875/> <Direction id=id3Name=Z directionDirection_ratios=0 0 1/> <Direction id=id4Name=X directionDirection_ratios=1 0 0/> </iso_10303_28_terse>
Sample Part 28 Program
The program below reads a STEP file (Part 21 or Part 28) and writes it back out to a different name and format. Including rose_p28.h and calling rose_p28_init() forces the program to recognize Part 28 as well as Part 21.
#include <rose.h>
#include <rose_p28.h> // bring in Part 28 support
void main(int argc, char ** argv)
{
rose_p28_init(); // call at start of program
if (argc != 4) {
printf ("usage: format <p21|p28|p28-raw> <in-name> <out-name>\n");
return;
}
const char * fmt = argv[1];
const char * in_name = argv[2];
const char * out_name = argv[3];
RoseDesign * d = ROSE.findDesign(in_name);
if (d) {
d->path (out_name);
d->format(fmt);
d->save();
}
else printf (ERROR: Could not read design '%s'\n
, in_name);
}
To build this sample program, compile normally, but add the rosexml library to the link line as shown in the following commands:
On UNIX and MacOS % CC -I$ROSE_INCLUDE format.cxx -L$ROSE_LIB -lrosexml -lrose On Windows > cl /I"%ROSE_INCLUDE%" format.cxx /LIBPATH:"%ROSE_LIB%" rosexml.lib rose.lib
Browsing Part 28 XML
ST-Developer makes it simple to examine STEP XML files in any web browser with the Part 28 to HTML conversion tool. On Windows, this tool integrates into the Explorer so you can open a file in a web browser by simply right clicking on it and selecting Browse P28 XML as shown below.
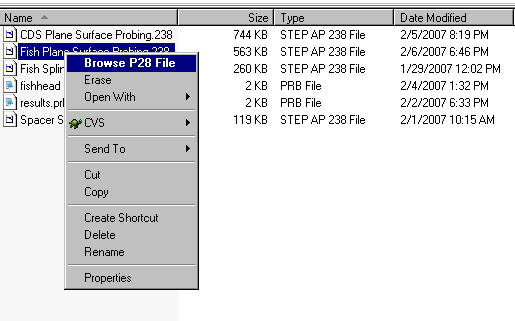
On other platforms just run the p28html command-line tool to prepare HTML for your browser as shown below
% p28html datafile.p28 ==> writes datafile.html in the current dir % firefox datafile.html
All of the entity instances are linked, so you can move through the file simply by clicking on references. As shown in the figure above, clicking on any instance in the file pops up a window showing all attributes, their types and their values, even unset attributes. You will also see a complete USEDIN() listing of objects that refer to the instance, and can quickly jump to any of them.
XML Configuration
The ISO 10303-28 file format uses the terse
configuration shown below.
<?xml version=1.0?> <configuration xmlns=urn:oid:1.0.10303.28.2.1.2xmlns:xs=https://www.w3.org/2001/XMLSchema> <schema targetNamespace=urn:oid:1.0.10303.238.1.0.1/> <option exp-attribute=attribute-contenttagless=true/> <uosElement name=iso_10303_28_terse> <add_attribute name=schematype=xs:NMTOKENusage=required/> </uosElement> </configuration>
The configuration uses the Part 28 attribute-content and tagless
encoding options and defines the iso_10303_28_terse unit of
serialization (UOS) element to enclose the instance data.
The targetNamespace
configuration for the element is based on
the ASN/1 identifer for the appropriate STEP Application Protocol
(AP238 in the example above). The element also has a schema
attribute with the schema name as in the header of a Part 21 file, to
simplify processing by EXPRESS-based tools.
The Part 28 namespace for an AP can be specified in the compiled EXPRESS data dictionary by using the -p28ns flag within a workingset file provided to the expfront compiler. If none is provided, XML will be written in the default namespace.
# Sample workingset file entry
SCHEMA config_control_design \
-p28ns urn:oid:1.0.10303.203.1.0.1
Alternatively, an application can specify a hook function to provide a namespace when writing a design. The function is called with a pointer to the design and first schema. The string return value will be the namespace. If the function returns null, no default namespace will be used.
typedef char * (*RoseP28NamespaceFn) (
RoseDesign * design,
RoseDesign * schema
);
extern RoseP28NamespaceFn rose_p28_get_namespace_fn();
extern void rose_p28_put_namespace_fn (RoseP28NamespaceFn fn);
The functions above get and put the namespace hook function. Putting a null function pointer will reset the behavior to call the rose_p28_dflt_namespace() function.
For handling the schema names in the schemas
attribute, the
Part 28 reader and writer use the Part 21 schema
hook functions.
ROSE Working Form Files
ROSE working form files are only used to save compiled EXPRESS data
dictionary information. They contain the same information as a STEP
Part 21 file, plus globally unique object identifiers, inter-file
references, and a root
object.
ROSE working form files are written in binary form. An ASCII form is used by the display() function when printing an object to stdout. Both file formats are written with the .rose or .ros filename extension. Files may be converted between Part 21 and ROSE with the rose format utility:
% rose format <fntname> <filename> % rose format step foo.rose - from ROSE working form to part 21 % rose format binary foo.step - from part 21 to binary working form % rose format rose foo.step - from part 21 to ascii working form
If you convert from ROSE working form to Part 21, you lose object identifier information, so you should never do this for the compiled EXPRESS schemas (the *.rose files produced by the EXPRESS compiler).
The binary format uses OIDs to find EXPRESS definitions, so if the compiled schema is deleted and regenerated, the new schema will have different OIDs, and any binary file that used the original will be unreadable.