This describes an older ST-Developer release (2012). You can find the details for the latest release here
Overview
Since 1991, ST-Developer has been the most complete and mature SDK for building STEP and EXPRESS applications. Our latest release, ST-Developer v15 continues this tradition by adding a new merged CAD library that covers the original AP203, AP203e2, AP214e3, and AP242. Using this, your programs can read files from any AP and switch between APs when writing.
In addition, STEP Part 21 file reading is 2-3 times faster, C++ programs use 10-20% less memory and we have cut memory use in half for Java programs. The C++ and Java libraries now have full international character support with UTF-8 strings for all string data and filenames, and the ST-Viewer library is multi-threaded to display geometry in a fraction of the time.
We have expanded sample programs and better Java support for IFC. Our utilities to analyze and resolve STEP assemblies will save you hours of time and trouble, and make it much simpler to start working with STEP geometry. We now support shared libraries for MacOS X and Linux on top of our already broad platform support.
ST-Developer continues to be the clear choice for building applications for STEP, STEP-NC, CIS/2, or IFC simply, distributing them easily, viewing, and verifying your data sets.
Supported Platforms
| Operating System | Architecture | Supported C++ Compilers |
|---|---|---|
| Windows 7/Vista/XP 32bit | Intel x86 | Visual Studio 2010 (VC++ 10.0), Visual Studio 2008 (VC++ 9.0), Visual Studio 2005 (VC++ 8.0), and Visual C++ 6.0 with the /MD option. |
| Windows 64bit | Intel x64 AMD64 EM64T |
Visual Studio 2010 (VC++ 10.0), Visual Studio 2008 (VC++ 9.0), Visual Studio 2005 (VC++ 8.0) with the /MD option. |
| MacOS X on Intel 32bit v10.4+ (Tiger) |
Intel x86 | GCC 4.0 (Xcode 2.3+, Xcode 3.x) |
| MacOS X on Intel 64bit v10.5+ (Leopard) |
Intel 64bit | GCC 4.0 (Xcode 2.3+, Xcode 3.x) |
| Linux LSB 3.x or newer distros, RHEL 4/5, SuSE 9+, and many others as described in the install notes. |
Intel x86 | GCC 3.4/4.x |
| Linux 64bit LSB 3.x or newer distros, built for x86_64. See install notes for examples. |
Intel 64bit AMD64 EM64T |
GCC 3.4/4.x |
| IBM POWER-series AIX v5.3 |
POWER5 | IBM XL C/C++ 64bit (default and thread safe) |
| Hewlett Packard HP-UX v11 |
Itanium | HP ANSI C++ 64bit (default and +Z -z -mt) |
| Solaris v10+ | SPARC | Sun Studio v11 64bit (default and -PIC -mt) |
| Solaris v10+ | Intel x86 | Sun Studio v11 64bit (default and -PIC -mt) |
Supported Application Protocols
ST-Developer v15 ships with a wide selection of C++ and Java class libraries, sample programs, HTML-documented schemas, and usage guides. This release adds support for AP242 and a new merged CAD library that covers the original AP203, AP203e2, AP214e3, and AP242. We are also ready to release an IFC4 library as soon as the final version is published.
You can start programming immediately, with out-of-the-box support for twenty three STEP Application Protocols, the CIMsteel Integration Standard (CIS/2) and two versions of the Industry Foundation Classes (IFC). Browse the full list, and if we missed your favorite, you can use the EXPRESS compiler and other ST-Developer tools to install them yourself!
Assembly Traversal Code
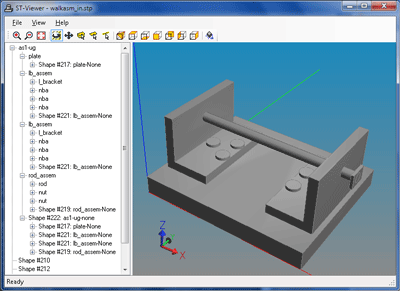
Assemblies are probably the most complex structure in STEP data sets. To process them correctly, you must look at relationships between products and relationships between shapes, watch for two different ways of describing placement of components (mapped item and context dependent shape reps), and resolve many other indirections.
In this release, we have included a complete reference program that analyzes the products, shape representations, and relations in a STEP file to identify assembly structures, then walks the structure printing the product, shape, and placement information. This program is drawn from the actual utilities used by ST-Viewer and other products. This code will save you a tremendous amount of time and trouble, and make it much simpler to start working with STEP geometry.
For more details, look at the WALK ASSEMBLY program included with the AP203, AP203e2, AP214, and AP242 sample programs. Within the program, several thousand lines of essential algorithms are packaged in single unit which you can reuse where it is needed.
Merged STEP CAD Library
The ST-Developer Merged CAD Library makes it simple to build one program that can read or write any STEP CAD model. The library has C++ classes for everything in the original AP203, AP203e2, AP214e3, and the most recent version of AP242.
Your programs can read files from any AP and switch between APs when writing. The library will automatically handle deprecated entities based on the schema you use. Finally, your application will not need ST-Runtime support files, because the library contains built-in data-dictionary information.
The library has classes for all types in the APs, functions to query and change the schema, and can write types with different names as AP conventions require. The first example below reads a file and prints some identifying schema information. The second function creates instances and writes files as different APs. The "applied_" assignments and other instances are written with the correct name for each AP.
The Merged CAD Library documentation has more examples and discussion.
void read_ap_file()
{
// Read a file and see what schema it was
RoseDesign * d = ROSE.findDesign ("testfile.stp");
switch (stplib_get_schema (d)) {
case stplib_schema_none: printf ("==> no schema set\n"); break;
case stplib_schema_ap203: printf ("==> AP203 file\n"); break;
case stplib_schema_ap203e2: printf ("==> AP203e2 file\n"); break;
case stplib_schema_ap214: printf ("==> AP214 file\n"); break;
case stplib_schema_ap242: printf ("==> AP242 file\n"); break;
case stplib_schema_other: printf ("==> Other type of file \n"); break;
}
}
void write_some_ap_files()
{
// Create some objects, and write as different APs
RoseDesign *d = new RoseDesign ("foo");
RoseObject * obj;
// Some geometry, common across all APs
obj = pnewIn(d) stp_cartesian_point;
// These assignments will be written as cc_design types in AP203
obj = pnewIn(d) stp_applied_approval_assignment;
obj = pnewIn(d) stp_applied_certification_assignment;
obj = pnewIn(d) stp_applied_contract_assignment;
obj = pnewIn(d) stp_applied_date_and_time_assignment;
obj = pnewIn(d) stp_applied_person_and_organization_assignment;
obj = pnewIn(d) stp_applied_security_classification_assignment;
obj = pnewIn(d) stp_applied_document_reference;
// Some contexts will be written as subtypes in AP203
obj = pnewIn(d) stp_product_context;
obj = pnewIn(d) stp_product_definition_context;
// Write as different APs
stplib_put_schema (d, stplib_schema_ap203);
d-> saveAs ("test_ap203.stp");
stplib_put_schema (d, stplib_schema_ap203e2);
d-> saveAs ("test_ap203e2.stp");
stplib_put_schema (d, stplib_schema_ap214);
d-> saveAs ("test_ap214.stp");
stplib_put_schema (d, stplib_schema_ap242)
d-> saveAs ("test_ap242.stp");
}
IFC Sample Code and Java Libraries
We have added several new IFC example programs with reusable code for creating GUIDs, units, spatial structure trees, and traversing relationships using backpointers. We provide C++ and Java versions of each sample program, so you can get started quickly no matter which language you prefer. There are two progams for making new data and two for reading and working with existing data:- Geometry - Create an IFC building with a simple block shape in C++ and Java. Also makes GUIDs, owner history, units, and basic spatial structure.
- Hello Wall - Create a standard wall and attaches property sets and quantities to it.
- Print Spatial - Recursively print the spatial structure defined in an IFC file, beginning with the IfcProject root.
- Print Wall Props - Find and print the properties associated with each IfcWall instance in an IFC file.
The Java libraries for IFC 2x3 and IFC 2x2 now have class names and function names that preserve the CamelCase symbols from the original EXPRESS. This should make it clearer and easier to use when writing new code. You can see the difference between the old and new naming conventions below. If you have a large body of existing code and prefer the old naming convention, you can generate classes with the old names using express2java.
// new names, preserving CamelCase IfcBuilding bldg = pop.newIfcBuilding(); bldg.setGlobalId (makeGuid()); bldg.setOwnerHistory (makeOwnerHistory(pop)); // old names, forcing to lower Ifcbuilding bldg = pop.newIfcbuilding(); bldg.setGlobalid (makeGuid()); bldg.setOwnerhistory (makeOwnerHistory(pop));On top of these IFC-specific changes, we have also made many other improvements to the Java library, mostly in response to IFC usage. These improvements will make IFC files easier to process, read faster, and use less memory.
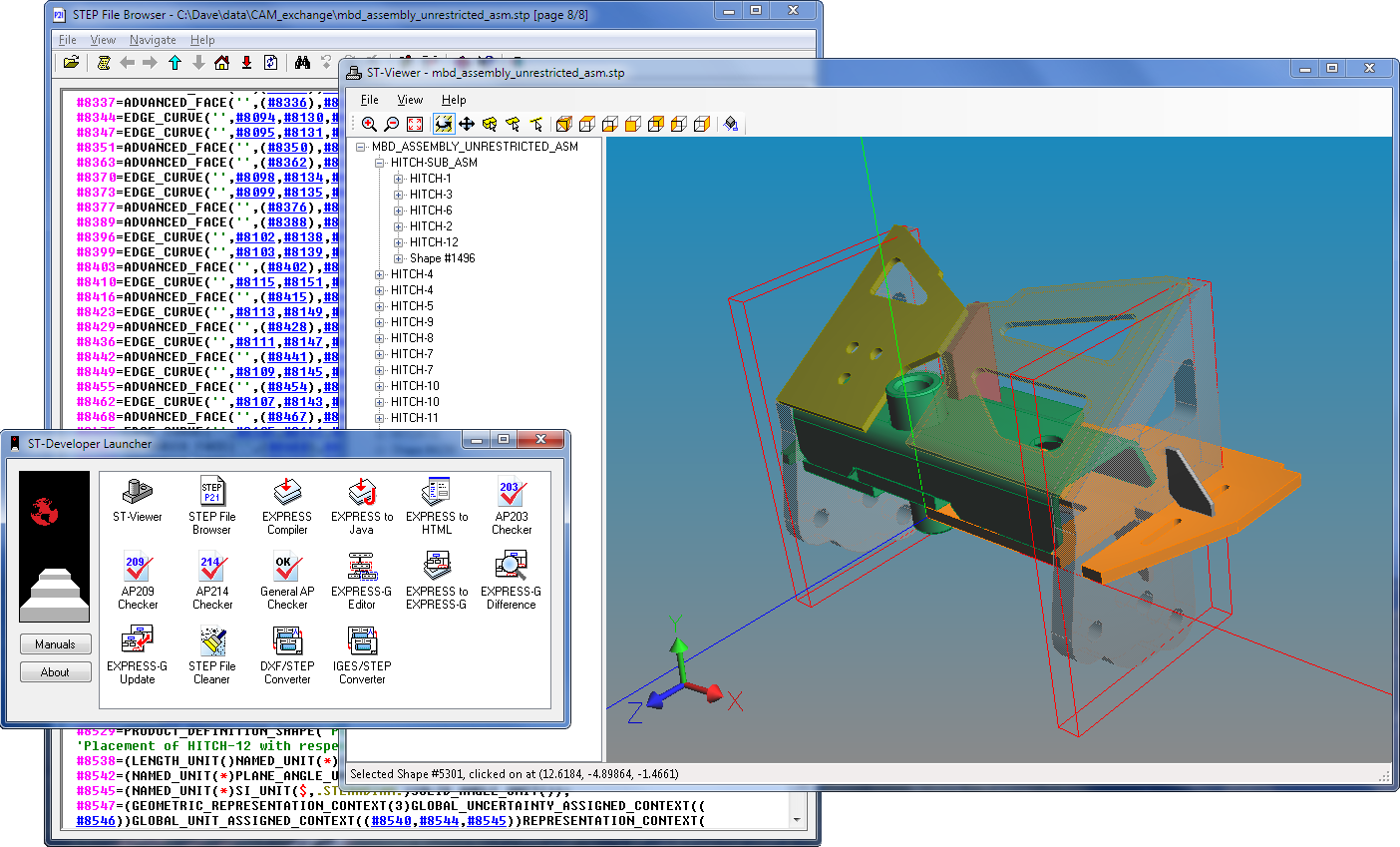
ST-Viewer Improvements
The ST-Viewer is based on a .NET library that that you can use to add STEP visualization to your .NET Forms applications. The ST-Viewer library lets you explore the product and shape assembly trees in a STEP file, turn assembly components on or off, and change the display color or transparency of things. The library displays STEP geometry with both context-dependent shape representation and mapped item assemblies, color information, and AP203e2 presentation tolerances. The ST-Viewer Reference Manual has a complete description of these capabilities.
This library uses the same STEP geometry visualization technology
found in our STEP-NC
Machine product, and this release of ST-Developer folds in the
many visualization performance and coverage improvements that we have
made over the past year. In particular, the library is now
multi-threaded, using any extra processor cores to to facet the STEP
geometry. These changes, combined with faster STEP
file reading means that ST-Viewer now reads and displays models
dramatically faster than before.
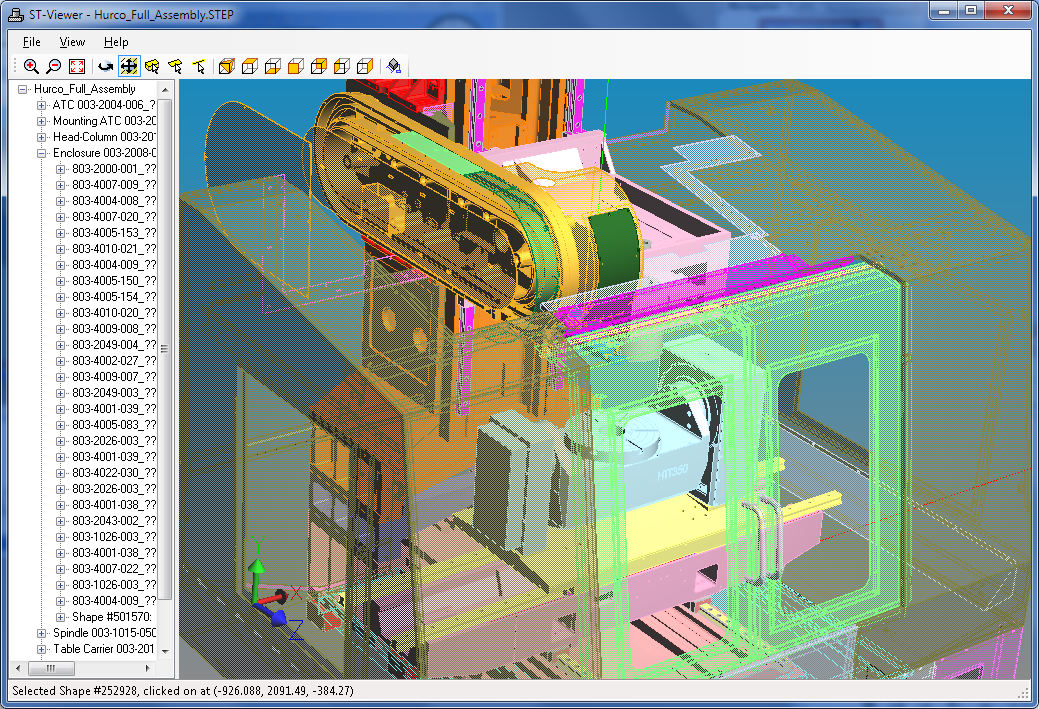
Faster STEP File Reading
Within the ROSE library, we have reorganized the Part 21 file reading code so that large files are now read in half to a third of the previous time. These improvements will be transparent for most applications -- Just enjoy the quicker reads! Some small code changes may be needed applications that use custom file handling features as described below.
This rework adds internal support for block reads from other data sources, like network connections or compressed files. This is done through the new RoseInputStream class, which is used by the RoseP21Parser and RoseP21Lex classes.
Custom comment parsing functions for the RoseP21Lex::comment_fn hook must be changed to use the new stream object instead of a FILE*. Instead of using stdio functions, simply read and push back characters using the get()/unget() functions on the stream() object associated with the lexer. The following member functions have also changed:
RoseP21Parser::readDesign() changed FILE* to RoseInputStream* RoseP21Lex::process() changed FILE* to RoseInputStream* RoseP21Lex::file() removed RoseP21Lex::stream() added, returns RoseInputStream*The new RoseInputStream class has a refill() virtual function that is implemented by subclasses. The RoseInputFile subclass implements a stream based on a FILE* structure, while the RoseInputString stream subtype implements a stream based on static string data.
International Character Support
The ROSE C++ library and ST-Developer Java library now fully support international characters in STEP data.
All ROSE C++ functions that take or return char* values now use UTF-8 encoded Unicode characters. When reading or writing data files, the library converts between UTF-8 strings in memory and the "/X2/" or "/X4/" hexadecimal format used for Unicode data in Part 21 files. It can also read Part 21 files with strings containing ISO 8859 "/S/" notation characters and convert them to the UTF-8 strings. Similarly, functions that take filenames now expect UTF-8 strings for wide character filenames.
With this change, we have retired the stepi18n.h header and all functions related to the previous technique for handling wide characters, which used Part 21 escapes in runtime strings as a kind of pseudo UTF-8 encoding. The retired functions are below:
rose_contains_encoded_wchar() // retired rose_cvt_p21_to_wchar() // retired rose_cvt_wchar_to_p21() // retired rose_enable_wchar() // retired rose_get_wchar() // retired
Unix applications should already be using UTF-8 strings when international characters are needed. On Windows, programs can use MultiByteToWideChar() and WideCharToMultiByte() with the CP_UTF8 flag to convert between wchar_t and UTF-8 strings where needed.
The Java runtime natively uses UTF-16 strings to handle international characters. The ST-Developer Java library has been updated to convert international character set data to and from the Part 21 file representation when reading or writing files.
Other ROSE Library Improvements
In addition to the speed boosts for file reading we have introduced optimizations that trim the already-low memory usage of the ROSE library. By tightening memory use during Part 21 reading, improving alignment on 64bit machines, and moving some data into managers, your applications will now use 10-20% less memory for the same data sets.
We added the RoseConstCursor subtype of RoseCursor, for use with constant data (no pnew, delete, or moves). This is safe to use in multiple threads. The default RoseCursor is not thread safe because it builds certain structures to deal with object addition and deletion.
RoseConstCursor objs;
RoseObject * obj;
objs.traverse (design);
objs.domain (ROSE_DOMAIN(some_type));
while ((obj=objs.next()) != 0) {
// read-only traversal of a design
}
In addition to the Part 21 speed improvements, the library now reads and writes Part 21 files correctly even if a programmer has called setlocale() to change the behavior of number formats (123.4 -> 123,4) and such. Previously, you had to switch back to the "C" locale before reading or writing. The library also reads numbers with doubled dots from email corruption (eg 1..234) and numbers missing dots before the exponent (eg 1E5 instead of 1.E5).
We also added the RoseP21Parser::set_schemas_fn function hook for custom schema handling and deprecated the RoseP21Parser::add_schema_fn hook. The new hook is called once with the list of all schema names, so your code can check for an empty list or certain combinations of names when assigning schemas. The original hook was called one by one on each name, and was never called if the list was empty.
Another addition is the RoseP21Writer::fill_column variable for changing or disabling the line wrapping in Part 21 files. Note that disabling wrapping is a bad idea because it makes the files more vulnerable to corruption when emailed.
We have improved the way that the ROSE library matches EXPRESS definitions to C++ classes, which makes the library more robust when mixing EXPRESS models that may have similar type names. This avoids conflicts observed when mixing STEP APs with ISO 13399 or the IGES converter schema. It now looks for classes using a schema qualified name ("schema.type") first, which prevents conflicts from definitions with same name in different schemas, say a POINT in FOO_SCHEMA and one in BAR_SCHEMA, but different C++ class names (FooPoint and BarPoint).
We also make sure that domains are only matched to classes that share the same I/O type (RoseNodeType) Now forcing best-fit classes for basic mismatch (entity/select, or entity/enum) as well as aggregates of mismatched types.
The string functions listed below have been renamed with rose prefixes to avoid potential namespace clashes. The RoseStringObject rw_str() and ro_str() functions were also deprecated in favor of new as_char() and as_const() functions.
strcmp_as_lowercase -> rose_strcmp_as_lower strcmp_as_uppercase -> rose_strcmp_as_upper strcmp_insensitive -> rose_strcasecmp strncmp_insensitive -> rose_strncasecmp hash_insensitive -> rose_hash_insensitive strcenter -> rose_strcenter strtoupper -> rose_strtoupper strtolower -> rose_strtolower
Changed rose_vector::size(), capacity(), and get() methods to const to allow const rose_vector * usage.
See Migrating Programs from Earlier Versions for a complete list of changes if you are upgrading code written for an earlier version of ST-Developer. We also addressed the specific issues listed in the table below.
Java Library Improvements
We have made many improvements to the ST-Developer Java interface to increase performance, scalability, and usability of the API. The library now uses much less memory. On average, a given data set now uses half the heap space as the previous versions, while cartesian points and other small lists can use 75% less memory.
EXPRESS aggregates have always been implemented with the Java Collections Framework, but now we use generics so the get, set, and add members are strongly typed. For example, SetCartesian_point now implements java.util.list<Cartesian_point>. These changes eliminate the unchecked cast warning that appeared in previous versions, and make it simpler to use the enhanced Java for loops as shown below:
/* Iterate over the control points of a spline */
for (Cartesian_point pt :spline.getControl_points_list()) {
/* Process each point */
ListReal coords = pt.getCoordinates();
...
}
The EXPRESS to Java class generator now has a "-preservecase" option which does not change the capitalization of EXPRESS symbols when generating classes and access functions. We use this for the IFC 2x3 Java libraries so they preserve the CamelCase symbols in the original EXPRESS.
Part 21 file reading and writing is faster, more robust, and now handles all international character set data using UTF-16 Java strings (including surrogate pairs). The file reader also now handles ISO 8859 characters (\P and \S escapes in a Part 21 file) and converts them to Unicode (ISO 10646) characters. The parser and writer now have hooks to monitor progress and possibly cancel the operation. You can do this by subclassing Part21Parser or Part21Writer and implementing a statusUpdate method, and then setting the status_freq field to indicate after how many instances read or written the system should call the statusUpdate method.
/*
* Flag variable: may be updated by another thread.
* If this is set to true, the P21 parse will abort.
*/
volatile boolean cancel = false;
/* Anonymous subclass of Part21Parser. */
Part21Parser parser = new Part21Parser() {
{status_freq = 200;} /* how often to call statusUpdate() */
public void statusUpdate(Part21Parser.State st)
throws CanceledException
{
if (cancel) throw new CanceledException();
float fract = st.getFractionRead();
String msg = String.format("%d%% done: %d instances read",
(int)(fract*100.f), st.getInstancesRead());
System.out.println (msg);
}
};
parser.parse("bar.stp");
The Part 21 parser now has better error recovery and reporting, with more options for continuing after syntax errors and providing error messages to the end user. Previously the first syntax error caused the entire read to be aborted with an exception. This is the default behavior for Part21Parser, but you can now use Part21LoggingParser or a custom subclass of Part21Parser for more flexible error reporting. We recommend that the logging parser be used instead of Part21Parser in simple applications. In more sophisticated applications, you can subtype Part21Parser yourself, and override a reportError() method, which will be called whenever the parser encounters an error.
/* Create a parser and read the file data.ifc */
Part21LoggingParser parser = new Part21LoggingParser();
Model mod = parser.parst("data.ifc");
Updating Java Programs from Previous Versions
There have been many internal changes to the libraries in this release, so you must completely recompile your source code. This release also requires Java SE version 6 or later. In most cases, your existing source code will continue to work with the new libraries, but there are a number of API changes that may require changes to your application
If you use the pre-built libraries included with ST-Developer (ap203lib.jar, ifc2x3lib.jar, etc), make sure that you have the v15 version in your classpath. If you generate your own classes from EXPRESS using the EXPRESS to Java compiler, you must regenerate the classes with the v15 compiler. We have changed the interface between the generated classes and the core class library and old code is no longer compatible. As mentioned above, the pre-built IFC class library now uses the CamelCase symbols as in the original EXPRESS. This should make it clearer and easier to use when writing new code. If you have existing code and prefer the old naming convention, you can generate classes with the old names using express2javaOther changes that may affect your application:
- The API now returns collections instead of arrays. We now use generics in the collections, so the API can return strongly-typed unmodifiable collections, without extra copies to protect of the data. In particular, this can be seen in the EntityDomain class with the getAllAttributes(), getAllSupertypes(),getKnownSubtypes(), getLocalAttributes(), getLocalSupertypes(), and the SelectionBase.getSelections() functions.
- The Part21Writer.parse() method now throws STDevException. Previously it did not throw any checked checked exceptions.
- The TypeException class is now a subtype of java.lang.ClassCastException. This will allow aggregates to conform to the contract of the Java Collections Framework while still throwing an ST-Developer specific type conversion exception.
- The SelectTypeException class is now a subtype of TypeException (and thus a subtype of java.lang.ClassCastException.
- The constructor of EntityIDTable is now private. Application code should always have been creating the table using the EntityIDTable.forModel() static method, but now this is the only way to create the EID Table.
- The AggregateObject.getInstances() method was removed from the API. This was a utility method that was of dubious utility.
- The type of entity instance IDs was changed from a BigInteger to int to save memory.
- Reorganized the type hierarchy for Aggregate. Aggregates of BINARY, BOOLEAN, LOGICAL, and STRING are now implemented as subtypes of AggregateObject. Previously, they were implemented as direct subtypes of Aggregate. This change should not affect the user code.
- Reorganized entity instance classes and populations. Instances now are actually contained in a population. This change resulted in savings of about 4-5 words per object due to the elimination of a hash table. This change also means that we have the EntityInstance.getPopulation() method added to the API. It is no longer possible to associate a single instance with multiple models, as it was in previous releases.
Additional Java Library Changes
Added line-wrapping code to the Part 21 writer. The writer will now insert newline characters into the file to keep each line in the file from getting too long, while insuring that a line never begins with a dot character (to protect the Part 21 file from corruption if it gets sent through e-mail). This change results in a similar behavior to the C++ version of the Part 21 writer.
The class generator and Part 21 filer now properly support data sets containing nested selects with intermediate defined types.
Updated the Part21 parser and writer to use Input/Output streams instead of Reader and Writers, explicitly using US-ASCII as the character encoding. This will make the filer more robust against any locale settings that run-time environment my provide.
We added the Part21Writer.update_timestamp field that, if false, prevents the writer from updating the timestamp in the Part 21 header. This can be used by applications the need to control the value of the timestamp in header, and need to value to be something other than the current date and time.
The Part 21 schema processing was updated to ignore the OIDs and other data that appears after the schema name in the header. Previously, this could have caused a read exception.
Implemented support for multiple data segments in the Part 21 reader and writer. The API was already there, but this feature was not implemented in earlier versions.
Fixed a bug where user defined entities (Part 21 keywords beginning with "!") were not recognized were causing the parser terminate with an exception. User defined entities are now ignored by the reader.
Added the trimToSize() method for all aggregates to optimize the storage, and updated the Part 21 Parser to use it after reading an aggregate.
Added conversion functions to Part21Parser to handle some common type errors. (e.g. REAL attributes written as INTEGERS, etc.) This infrastructure is available to applications via the Domain.convertTo() method.
Updated AggregateReal and AggregateInteger to use a custom implementation rather than using java.util.ArrayList. These classes are the supertypes of all the EXPRESS aggregates of REAL and INTEGER. This allows us have the buffer implemented as a array of the primitive types rather than requiring the use of a wrapper Double or Integer object for each element, with a significant memory savings per aggregate.
The AggregateObject class was updated to be a subtype of java.util.ArrayList. Previously, the object contained a reference to the ArrayList. This change saves about 3 words of storage per aggregate.
Created com.steptools.stdev.impl namespace for implementation-specific (private) classes. Moved DynamicEntityDomain, EntityInstanceImpl and other internal classes to this namespace.
Removed the factory methods for AND-OR part creators from the generated Schema and Population classes. These were never part of the public API, and their presence caused some confusion.
Eliminated the object to entity ID mapping in the EIDTable instead added a field to the instance to hold the EID, eliminating the need for a hash table, and saving memory. (The API get the the entity ID of an object is still supported, just the data structure has been changed.)
The Population.getFolder() does not return null anymore when the folder is empty. It now returns an empty folder.
Added EntityIDTable.removeTable() to remove an EntityIDTable from a Model and reclaim the memory the table was using.
Added additional usedin methods making the scope parameter optional. If the scope is not specified (or it is null), the Population containing the instance is used as the scope.
Added getPopulation() method to EntityInstance.
Fixed bug where illegal AND-OR domains were getting created when the same supertype was being passed in multiple times (bug #297).
Removed the keystone.Schema object. This means that importing both keystone.* and an EXPRESS generated schema will no longer result in the Schema symbol being hidden since it appears in both namespaces.
Updated Javadoc to include on-line links to Oracle's Java API documentation.
Added EnumerationDomain.getItems(), to get the set of enumerations that defined an EXPRESS ENUMERATION type.